How to turn images into text with Optical Character Recognition (OCR) in R

Optical Character Recognition (OCR) is a way of turning pictures of words into actual words on your electronic device. For example, OCR can turn a photo of a book page, or a bad photocopy of a PDF, into actual words and characters you can edit.
In fact, Microsoft Office already has basic OCR. If you have a very clear and well formatted PDF, then you can scan it into Excel. However, oftentimes we have to work with unclear, poorly formatted documents. These cases require stronger tools.
One such tool is the free and open-source Tesseract. Tesseract can turn pictures of words into text on your computer, but it's not the best at turning them into well formatted paragraphs. However, there is a tesseract package for R, which can help us do just that.
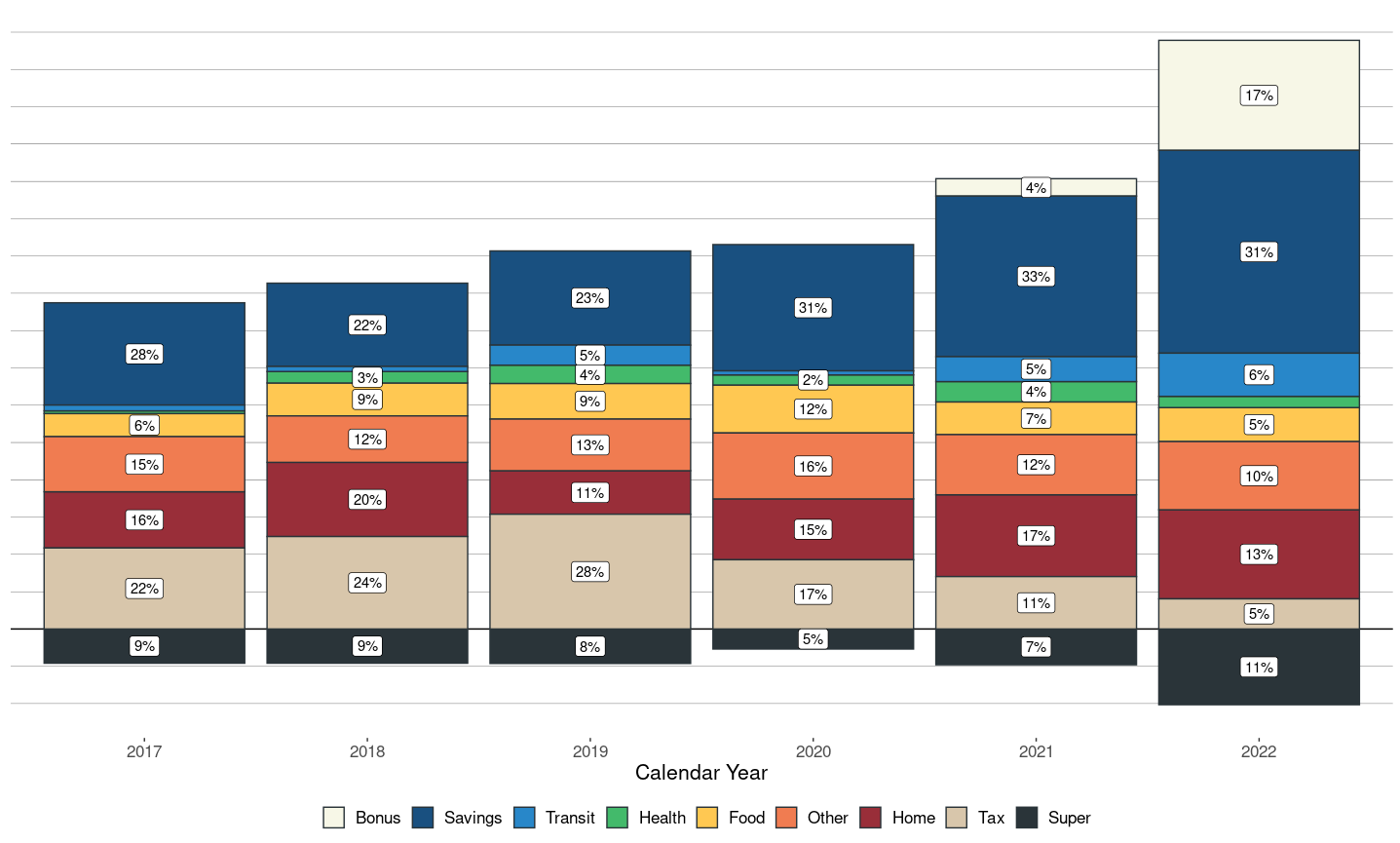
I used Tesseract to scan a few months worth of my bank statements into a spreadsheet. In the old times, I would have poured a strong black coffee and manually entered the data manually over a week With Tesseract OCR, I polished this off in a few hours.
Here's how you can do it.
What you need
- Follow these instructions to install Tesseract on your machine. Tesseract runs on Windows, Mac & Linux. I used Linux, but you should be able to adapt this for whatever OS you use.
- Install R & RStudio on your machine. You will need to install the packages:
tidyverse,tesseractandmagick.
Step-by-step guide
In this guide, I assume you have already installed Tesseract using the instructions above. We'll also use this guide to read a multi-page PDF, rather than an image, because if you learn how to run OCR on PDFs, then you will know how to run it on images too.
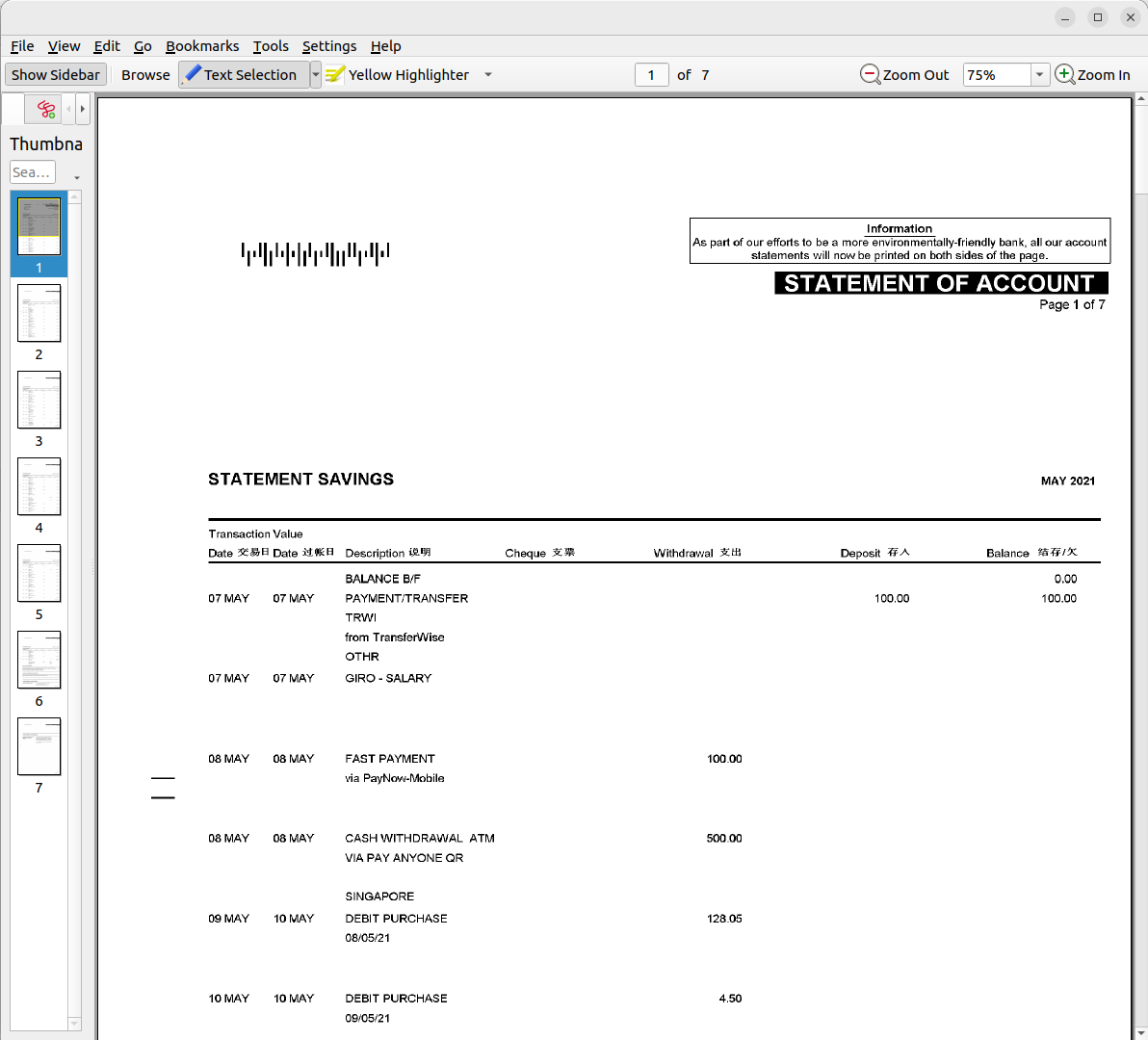
1) Save your PDF (or images) in a folder
We're going to tell R to split our PDF up into one image for each page and save those images in a folder on our hard drive. So, first up, put your PDF in that folder.

In this case, the PDF is one month of bank transactions. The scan that the bank sent me is clearly a photocopy of a print out, which looks alright to the human eye, but it's impossible for Excel to convert this.
2) Setup your R environment
First we load the packages we'll need. I'd already installed these packages, so you may need to install them using install.packages() first. I'm using here:: for my folders, but this is optional.
devtools::install_github("ropensci/magick")
pacman::p_load(
install = F,
update = F,
char = c(
"here",
"tidyverse",
"magick",
"tesseract"))
3) Rev your OCR engines
Next we need to tell our Tesseract package what language we're going to convert from image to text. In this case, my PDF contains both English and Mandarin, but we only need to read the English characters. Therefore we'll load the eng engine using this code:
tesseract_english <- tesseract("eng")
4) Convert your PDF to images
Now Tesseract can only convert images, not PDFs, to text. So we need to convert our PDF to a series of images. The pdftools::pdf_convert() function allows us to turn each page into an image and save a list of the images' filenames.
ls_pdf_pages <-
pdftools::pdf_convert(
dpi = 600, # Image resolution. Play around with different DPIs
format = "png", # Image format, also supports "jpeg"
pdf = file.path( # State what file are we converting
here::here(),
"Input",
"Example Bank Statement - May 2021.pdf"))
Which if it works should give you something like this output, where each image is one page of the PDF.
Converting page 1 to Example Bank Statement - May 2021_1.png... done!
Converting page 2 to Example Bank Statement - May 2021_2.png... done!
Converting page 3 to Example Bank Statement - May 2021_3.png... done!
Converting page 4 to Example Bank Statement - May 2021_4.png... done!
Converting page 5 to Example Bank Statement - May 2021_5.png... done!
Converting page 6 to Example Bank Statement - May 2021_6.png... done!
Converting page 7 to Example Bank Statement - May 2021_7.png... done!
Note that if your OCR is struggling to figure out what certain letters are, then try re-running the above with a different DPI. Sometimes the image is too blurry or too sharp and it's confusing Tesseract.
5) Create text by running OCR on all the images
Now we'll run a for loop over all the images we saved above and apply the Tesseract OCR to each one in turn. We'll also save all of the OCR outputs in one consolidated data frame as we go.
# Create an empty data frame (df) to write to
df_text <-
tibble()
# Read PDF pages
for (i in 1:length(ls_pdf_pages)) { # For all the images in our list...
ocr_output <- # ... create an object which is the OCR of that image
tesseract::ocr(
image = ls_pdf_pages[i],
engine = tesseract_english)
df_text <-
ocr_output %>% # Take the OCR outputs and ...
cat() %>% # ... con(cat)enate and print the text
capture.output() %>% # Capture the text output
as.data.frame() %>% # Convert it to df so we can bind_rows()
rename(text = 1) %>% # Rename column one to be named "text"
bind_rows(df_text, .) # Add the latest image's text to the end
} # This is the end of the loopAnd this gives us a data frame that looks something like...
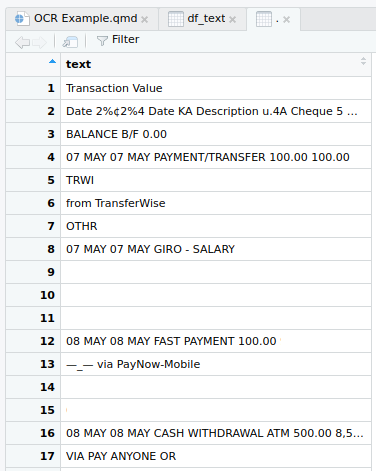
6) Transform the text into something readable
It's pretty impressive that R & Tesseract could convert the PDFs so well, but there are also some errors.
How well the text formats itself once its read will depend on your document. A simple paragraph probably won't require any formatting, whereas a table such as this requires quite a lot.
To start with, I'd start by stripping out unnecessary characters like underscores and dashes, as well as parsing the dates.
df_cleaned <-
df_text %>%
mutate(
text = stringr::str_replace_all(text, c("[_–—]"), ""),
text = stringr::str_replace_all(text, "\\. ", ""),
text = stringr::str_trim(text),
date = lubridate::parse_date_time(
paste0(str_sub(text, 1, 6), " 2021"),
"%d %b %Y"))
When I said I compressed the process down to a few hours, this data cleaning after running the OCR was the bulk of the time. I won't take you through all that cleaning because you don't need it, you already have everything you need to run your own OCR on your own PDFs.
Best of luck!
Acknowledgements
I worked my way through the code myself, but I couldn't have done it without these helpful people and their patient instructions: